データセット
今回解析の対象となったコメントデータは以下のような特徴を持ちます:
コメントデータベース
・1/4/1999 ~ 3/2/2016の間にガーディアン紙のサイトにて書き込まれたコメント。ソーシャルメディアなどでの記事への言及は含まない
・コメント総数7,000万件
・うち22,000件が2006年以前に書き込まれた。つまりほとんどがそれ以降のもの
・コメント欄は通常三日間オープンとなり、その間に読者が書き込める。それ以後は読むことのみ可能。したがって、ニュースに対する比較的初期のレスポンスがコメントとして集まる
・コメントは、モデレータにより「ブロックされたもの」と「通常のコメント」に分類されている
・実際のデータはPostgreSQLデータベースに格納
・解析にあたり、実際に新聞社のサイトで使われているデータベースをコピーしてAWS上にアップロード
ブロックと削除の違い
記事がサイトに表示されない場合、それはガイドラインに沿ってブロックされたか、削除されたのかどちらかとなります。今回の解析では、データとしては残っているが、内容がガイドライン違反なので非表示とされたコメント、すなわちブロックされたコメントをその記事に対する煽り・嫌がらせとしてカウントしています。
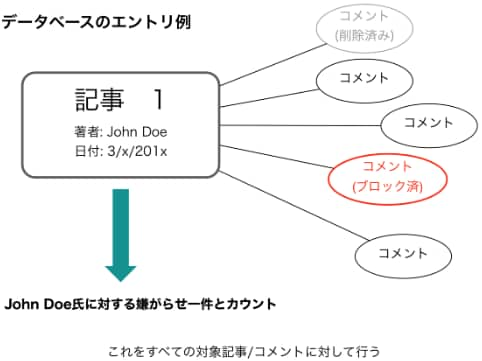
逆にデータに残っていない(したがって今回利用されていない)削除の対象となったコメントは「ブロックされたコメントへの返信」「単純なスパム」となっています。
記事のデータベース
コメントは記事に対して書き込まれます。したがって、記事が誰によって書かれたのか、どのような内容だったのかということを合わせて解析するためには記事のデータベースが必要です。ガーディアン社の記事データベースは以下のようなものです:
・オンライン版の記事総数はおよそ200万
・Amazon Web ServiceのRedshiftに格納
・このデータベースは公開APIに接続されていて、外部の人もプログラムから検索をかけることが可能
Amazon Web Serviceとは何か?
またここでもAmazonが出てきました。最近のプログラマは空気のように使っている技術ですが、それ以外の人にとっては「なんで通販会社が新聞社のデータ解析に関係あるの?」ということになりかねないので、ここで簡単に説明しておきます。
Amazonは本の通信販売の会社として始まりましたが、成長の過程で、その大量のオーダーを裁くために無数のサーバーを含む巨大なシステムを構築しました。そこを維持するためには、ハードウェア・ソフトウェア両面の様々なノウハウが必要なのですが、先見の明のあったAmazon社の社長は、そのノウハウをベースに構築された高度な計算機システムを、外部の人に時間貸しという形で提供するビジネスを思いつきました。それがAmazon Web Service (AWS)と呼ばれるサービスです。これを解説し始めると本1冊以上の分量になってしまうので詳細は割愛しますが、企業はこれを利用することにより、自社内にサーバーを持って、データベースを構築して、バックアップを取って、電源を適切に管理して...という作業を外部化することができます。しかもありとあらゆるものが仮想化という技術をベースに抽象化されていますので、まるでソフトウェアを実行するように新しいサーバーを構築し、それをいらなくなったらコマンド一つで捨てる、ということが行えます。いわゆるビッグデータ(私はこの言葉の定義が非常に曖昧であるため、あまり好きではありませんが...)を解析するような場合、必要な量だけのストレージ、つまりデータの置き場を用意し、必要な数だけの計算機を時間単位で借りて一気に解析する、ということが可能です。
このような「時間貸し計算機」のサービスは、現在の大量のデータを生み出す社会の中で重要な役割を果たしています。AWSやその他の大手クラウドコンピューティングサービスは世界中のあらゆる企業によって使われています。また企業ばかりではなく、私の職場のような非営利の研究機関でもこのサービスは利用されています。大量の塩基配列情報を処理するのに、安い時間帯(AWSは、時間によって値段の変動するオークション形式も採用しています)に一気に多数の計算機を借りて解析を実行する、というようなことも始まっています。
ガーディアン社でのAWSの利用
ここでガーディアン社の使っているAmazon Redshiftと呼ばれるサービスは、いわゆるデータウェアハウスを外部に構築する際に使われるものです。新聞社にとって命とも言える記事のデータを全てここに格納し、解析や検索が行える状態になっています。社内の解析チームが直接使っているものとは異なると思いますが、この記事データベースは一般の方にも開放されています。英語ですが使い方も書いてありますので、興味のある方は遊んでみてはどうでしょう。ちょっと試すだけなら、ブラウザからもアクセスできます。

このデータベースに対して適切な検索条件を送信することにより、著者のデータも得ることができます。今回は「最低2回はガーディアン紙上に記事を書いたことのある人」という条件で著者名のリストを得ました。その総計はおよそ12,000人でした。しかしここで問題が一つあります。今回の仮説は男女の差に関わるものなのに、著者の性別はデータベースには存在しないのです。この問題を彼らはどう解決したのでしょうか?













