著者の性別の判定
今回、最終的に検証したい仮説が性別に基づくバイアスなので、著者の性別がわかっていないとどうにもなりません。この問題を解決するために彼らが行ったのは、ある意味とても原始的な作業でした。しかし技術的には高度でないにもかかわらず、この類の作業というのがデータ解析を行うときに最も面倒で時間のかかる作業であるケースも非常に多いです。つまり、一定のエラーを含みながらも必要な結果を得られる程度には正確な、形成されたデータを作るという作業です。
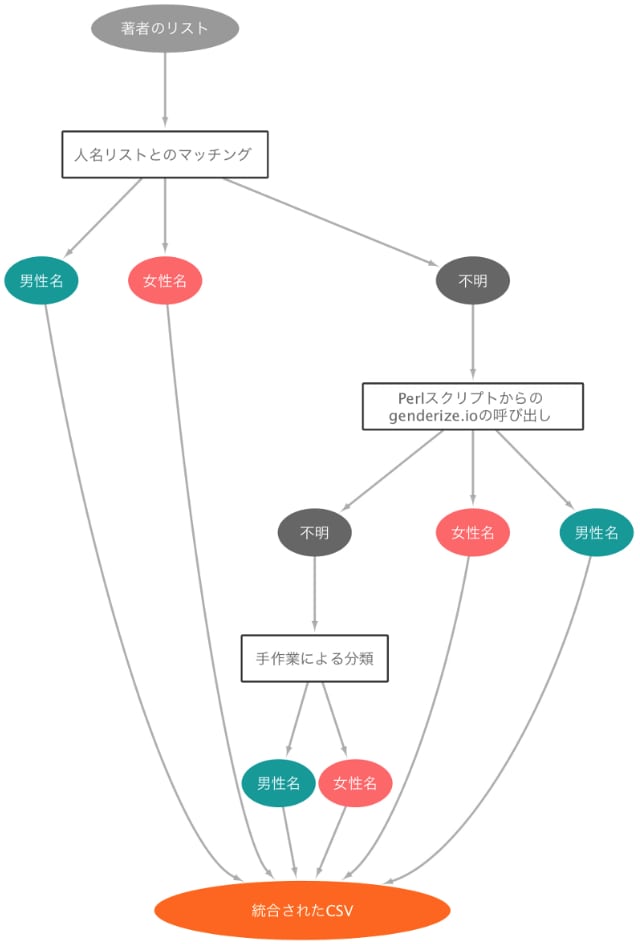
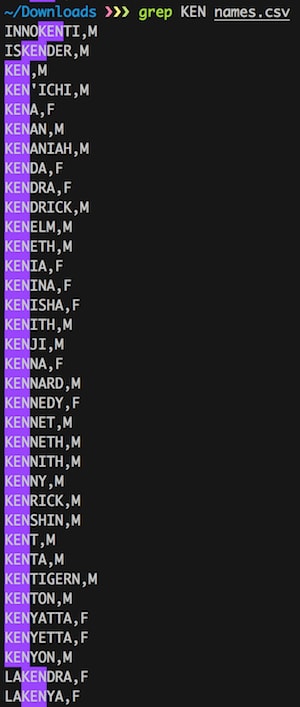
今回の具体的な作業は上の図のようになります。まず12,000人の著者名を、無償で公開されている男女別の人名リストと比較するスクリプトを実行します。おそらくここではファーストネームの完全一致による単純な判別を行っていると思われます。これにより、11,098人分のデータが男女別に分類され、1,268人が性別不明として残りました。性別不明になる原因は色々と考えられるのですが、そもそも名前がリストにない場合はわかりませんし、名前の英語表記の揺れなども原因になります。例えば、下のスクリーンショットは今回使われた名前のリストからの抜粋ですが、日本人名の「ケンイチ」という名前は、正しく男性名に分類されていますが、表記がKEN'ICHIであるため、KENICHIという表記との単純一致だと取りこぼしてしまいます。このような名前や住所といったものの表記ゆれは厄介な問題で、バラバラにデータベース化された情報を統合する時に様々な問題を引き起こします。
さて、この時点で不明の1,268人分のデータの性別を判定するために、今度は以下の人名判定サービスにPerlスクリプト(この場合は、Perlというプログラミング言語で作業工程を記述した小さなプログラムのことです)で送信します:
・genderize.io: Determine the gender of a first name
このサービスを利用した後の時点で何名ぐらいが性別不明だったかはわかりませんが、なんとか人力で判定、つまり人名辞典やネット検索で人間が一つ一つ判定するのも不可能ではない程度の量にまで不明の数が減っていたので、残りは実際にそういう作業で仕分けされています。「データサイエンス」という言葉の響きとは対極にあるような作業ですが、現実はこんなものです。
ともあれ、この作業で一定のエラーは含まれているが、それなりに大きい数の男女別著者リストが得られたので、そのファイル(CSV)をAWSのS3というストレージサービスにアップロードしました。ここからはAWS上の計算機での作業になります。













