解析の結果
はたして、その結果はうんざりするものでした:
The 10 regular writers who got the most abuse were eight women (four white and four non-white) and two black men. Two of the women and one of the men were gay. And of the eight women in the "top 10", one was Muslim and one Jewish.
And the 10 regular writers who got the least abuse? All men.
定期的に記事を執筆している記者のうち、最も多くの嫌がらせを受けた10人の内訳は、8人が女性で2人が黒人男性だった。そのうち2人の女性と1人の男性はゲイだった。その「トップテン」の8人の女性うち、1人はムスリムで、1人はユダヤ人だった。
そして最も嫌がらせを受けた回数が少なかった10人は、全員男性だった。
この結果を導き出したのは、計算機によるデータ解析でした。解析結果についても思うところはあるのですが、ここでは技術的な部分についてのみ注目してみます。実はこの記事に合わせて、解析チームの方がこの解析に使った手法についてかなり詳細に書いています:
対象とする読者
本稿ではこの記事に書いてある手法を、技術者ではない方に向けて解説してみます。ですからプログラマの方などが読まれると冗長に感じられるかと思いますが、そこはご勘弁を。専門家向けの記事と、「データ解析」という言葉が事実上「魔法」と同義語で使われている全く技術に触れない記事はたくさんあるのですが、その中間が埋まっていないように感じていたというのが執筆の動機の一つです。実例の解説は、その「魔法」にかかった靄を取り除き、実際の作業がどのくらい地味なものかを明らかにすることができると思います。
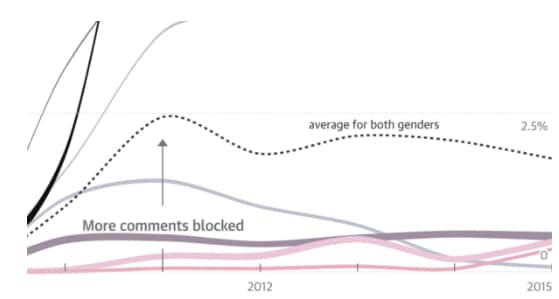
なお結果の詳細は、D3.jsを使ったインタラクティブなチャートとして元記事に掲載されていますので是非ご覧になってみてください。「ジャズや競馬[注]の話題に関しては穏やかなコメントが比較的多いが、フェミニズムやパレスチナ問題のコメント欄はかなり荒れる」と言う、どこかで聞いたような話だな...と思わず苦笑してしまうような事実がデータに基づき図表で解説されています。実際の嫌がらせの内容にも触れていますので、読んでいてあまり気持ちのいいものではない部分もありますが、「誰でも自由に発信できる世界」に対して記者の方々が払っているコストの生々しい実態が読めます。
[注]: イギリスの記事ですから、日本の競馬とは雰囲気や意味合いがかなり異なるので、そこは注意して読んでください 。

仮説検証のための技術
今回の分析では、複雑な統計解析は行われていません。最終的に得られたデータを可視化して、それを使って仮説が正しいかどうかざっと眺めるような作業になっています。基本的な流れとしては、手元にあるデータに欠けている情報を追加し、複数のデータセットを統合し、フィルタリングし、ブラウザ上で可視化するというものです。これは可視化を伴う分析を行う場合の最も基本的な作業です。ただし今回は比較的大きなデータを使っていますので、一部は商用クラウドサービス上でSpark(後述)を利用しています。ここからは実際に使われたデータやツール、手法について詳しくみていきます。

使われた技術
今回使われたツールは、データ分析を業務として行っている方々にはおなじみのものばかりです。例を挙げると:
・テキスト処理のためのPerlスクリプト
・Amazon Web Service (S3, Redshift, EMR)
・Apache Spark
・PostgreSQL
・D3.js
・HTML5
などです。これらのツールは以下のように分類できます。
・データを蓄積して検索可能にする技術: PostgreSQL, S3, Redshift
・データを加工するプログラム: Perlスクリプト
・大規模なデータを複数の計算機で処理する技術: Spark
・それらを実行するための環境を提供する技術: AWS全般, EMR
・最終的なユーザー(今回のケースでは読者)がデータをわかりやすく見られるようにする技術: D3.js, HTML5
これらが実際にはどう使われたのかは後ほど見ていきます。













