世界中で話題になっているパナマ文書。各国で政権を揺るがすような事態にもなっていますが、純粋にデータとしてみた場合、これは計算機やデータ解析に関わる人々にも面白いものだと思います。データの中身や背景などについてはさんざん報道されていますのでここでは触れません。一方、現場でどのような作業が行われているのかはあまり報道されていません。現実的な問題として、人力ではどうしようもない量のリークデータを手に入れた場合、調査報道機関はどんなことを行っているのでしょうか? 私も以前から疑問に思っていたのですが、先日あるデータベース企業と、データ分析アプリケーションを作成する会社のブログにて、その実際の一端を窺うことができる投稿がありました:
・Panama Papers: How Linkurious enables ICIJ to investigate the massive Mossack Fonseca leaks
・The Panama Papers: Why It Couldn't Have Happened Ten Years Ago
・Inside the Panama Papers: How Cloud Analytics Made It All Possible
これらは普段からグラフ(後述)を扱う仕事をしている自分にとっても興味深いものでしたので、ここで紹介します。こう言った現代の調査報道のテクニカルな部分は日本のマスコミで報道されることはほとんどないので、読んでいて純粋に面白かったです。ここでは世界の調査報道機関はどんなテクノロジーを使い何をやっているのかを、技術に明るくない人にもできるだけわかりやすいように書いてみようと思います。
データの形式
まず今回のデータの計算機的な性質です。公開されている情報によれば、それは以下の様なものです
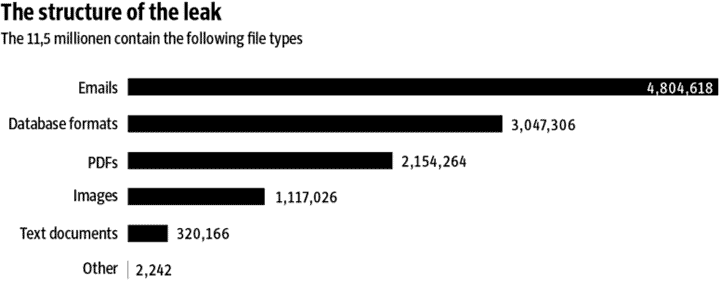
・容量: 2.6TB。大きさとしては一万円程度のハードディスクにすべて納まります。
・ファイル数: およそ1,150万
・データ形式: 電子メール、RDBなどのデータベース、PDF文書、画像(おそらく多くは書類のスキャン)、テキストファイル。ファイル数の分布は上のチャートを参照
2.6TBというデータは、現在の計算機にとっては決して大きなものではありません。貴方がテレビ録画用のHDレコーダをお持ちでしたら、おそらくこれより大きなデータをそこに格納できるでしょう。しかし、その大きさのデータを人間が解析しようと思った時、それはあまりにも膨大な量で、とても人力でどうにかなるものではありません。本質的にこのデータセットに対しては、プリントアウトしてひとつひとつ見るというようなアナクロな手法は通用しません。パナマ文書は何らかの検索や可視化の技術が利用できなければ、人間には歯が立たないものなのです。
しかし幸運なことに、今回のデータは画像ファイルを除けば(これも最近「インテリジェントな」解析技術が飛躍的に向上していますがここでは触れません)、ほぼすべてが機械で比較的低コストで処理できる形式のファイルです。ここで計算機の出番になります。ここから先は、先の記事から読み取れる技術的な背景について解説していきたいと思います。
データの前処理
このような膨大な数のファイルを解析する場合、必ずデータの前処理が必要になります。今回のデータセットは大きく二つのタイプに分けることができます:
1. RDB形式(いわゆるデータベース)の機械で容易にアクセスできるファイル
2. 人が読むことを前提にした文書ファイル。テキストと画像、PDFを含む
今回解析に当たったICIJのデータ解析班は、まず比較的ハードルの低いひとつ目のデータに取り組みました。要するに、データベースを容易に検索できる形に再構築することです。これは専門家の手により数ヶ月で終えることができたそうです。しかし二つ目のデータはそうはいきません。













